
机器学习领域的进步最近促进了计算工具的开发,这些工具可以创建令人信服但人工生成的文本,也称为深度伪造文本。虽然自动创建文本可能有一些有趣的应用,但它也在安全和错误信息方面引起了严重关注。
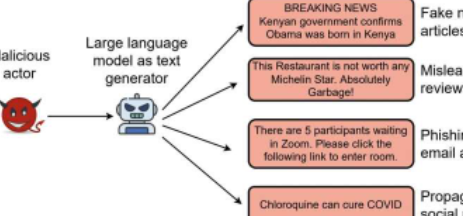
合成生成的文本最终也可能被用来误导互联网用户,例如通过大规模生成极端分子或旨在激化个人的暴力文本、用于虚假信息宣传活动的假新闻、用于网络钓鱼攻击的电子邮件文本或针对特定酒店的虚假评论,场所或餐厅。总的来说,这可能会进一步降低一些用户对在线内容的信任,同时促使其他用户从事反社会和危险的行为。
最近由弗吉尼亚理工大学的研究人员与芝加哥大学、巴基斯坦LUMS和弗吉尼亚大学的研究人员合作领导的一项研究最近探索了现有检测深度伪造文本方法的局限性和优势。他们的论文以学生JiamengPu和ZainSarwar为主要作者,将在IEEES&P'23上发表,这是一个专注于计算机安全的会议。
“我们在2016年之前进行的大部分安全研究都假设了一个算法较弱的攻击者。鉴于AI和ML取得的进步,这种假设不再有效。我们必须考虑算法智能或ML驱动的对手。这促使我们开始探索这个空间。2017年,我们发表了一篇论文,探讨RNN这样的语言模型(LM)如何被滥用,在Yelp等平台上生成虚假评论,”领导这项研究的弗吉尼亚理工大学研究员BimalViswanath告诉TechXplore。
“这是我们第一次涉足这个领域。从那时起,我们观察到LM技术的快速发展,尤其是在Transformer系列模型发布之后。这些进步增加了滥用此类工具的威胁,从而使大规模活动得以传播虚假信息、生成意见垃圾邮件和辱骂性内容,以及更有效的网络钓鱼技术。”
在过去的几年里,世界各地的许多计算机科学家一直在尝试开发能够准确检测高级LM生成的合成文本的计算模型。这导致引入了许多不同的防御策略;包括一些在合成文本中寻找特定工件的方法,以及其他一些依赖于使用预训练语言模型来构建检测器的方法。
Viswanath解释说:“虽然这些防御措施报告了很高的检测精度,但仍不清楚它们在对抗环境下的实际效果如何。”“现有的防御措施是在研究人员自己创建的数据集上进行测试的,而不是在野外的合成数据上进行测试的。在实践中,攻击者会适应这些防御措施以逃避检测,而现有的工作并没有考虑这种对抗性设置。”
恶意用户可以通过稍微改变他们的语言模型的设计轻松克服的防御在现实世界中最终是无效的。Viswanath和他的同事因此着手探索迄今为止创建的一些最有前途的深度伪造文本检测模型的局限性、优势和现实价值。
他们的论文重点介绍了过去几年推出的6种现有的合成文本检测方案,所有这些方案在初始评估中都取得了显着的性能,检测准确率从79.6%到98.5%不等。他们评估的模型是BERT-Defense、GLTR-GPT2、GLTR-BERT、GROVER、FAST和RoBERTa-Defense。
“我们感谢这些模型的开发人员与我们共享代码和数据,因为这使我们能够准确地复制它们,”Viswanath说。“我们的首要目标是可靠地评估这些防御在真实世界数据集上的性能。为此,我们准备了4个新的合成数据集,现在我们将其发布给社区。”
为了编译他们的数据集,Viswanath和他的同事收集了数千篇由不同的文本生成即服务平台创建的合成文本文章,以及由机器人创建的deepfakeReddit帖子。文本生成即服务平台是人工智能驱动的互联网站点,允许用户简单地创建合成文本,并且可能被滥用来创建误导性内容。
图片来源:Pu等人
为了可靠地评估他们选择的六种防御模型在检测deepfake文本方面的性能,研究人员提出了一系列“低成本”规避策略,这些策略只需要在推理时更改基于LM的文本生成器。这基本上意味着生成假文本的LM可以在试验期间进行调整或改进,而无需额外的培训。
“我们还提出了一种名为DFTFooler的新型规避策略,它可以自动扰乱或修改任何合成文本文章以逃避检测,同时保留语义,”Viswanath说。“DFTFooler使用公开可用的LM,并利用合成文本检测问题独有的见解。与其他对抗性扰动方案不同,DFTFooler不需要对受害者防御分类器的任何查询访问权限来创建规避样本,从而使其成为更隐蔽和实用的攻击工具”
该团队的评估产生了几个有趣的结果。首先,研究人员发现,在他们评估的6个防御模型中,有3个在真实世界的数据集上进行测试时,性能显着下降,准确率下降了18%到99%。这凸显了改进这些模型以确保它们能够很好地概括不同数据的必要性。
此外,Viswanath和他的同事发现,改变LM的文本解码(即文本采样)策略通常会破坏许多防御。这个简单的策略不需要任何额外的模型重新训练,因为它只修改了LM现有的文本生成参数,因此很容易被攻击者实施。
Viswanath说:“我们还发现,我们称为DFTFooler的新的对抗性文本操作策略可以成功创建规避样本,而无需对防御者的分类器进行任何查询。”“在我们评估的六种防御措施中,我们发现与其他防御措施相比,一种称为FAST的防御措施在这些对抗性环境中最具弹性。不幸的是,FAST有一个复杂的管道,使用多种高级NLP技术,因此更难理解它的更好的性能。”
为了更深入地了解使FAST模型在检测deepfake文本时特别有弹性和可靠的特性,研究人员对其特征进行了深入分析。他们发现该模型的弹性是由于它使用了从文章中提取的语义特征。
与本研究中评估的其他防御模型相比,FAST分析文本的语义特征,查看命名实体以及文本中这些实体之间的关系。这种独特的品质似乎显着提高了模型在真实世界的深度伪造数据集上的性能。
受这些发现的启发,Viswanath和他的同事创建了DistilFAST,这是FAST的简化版本,仅分析语义特征。他们发现该模型在对抗性设置下优于原始FAST模型。
Viswanath说:“我们的工作突出了语义特征的潜力,可以实现对抗性强的合成检测方案。”“虽然FAST显示出希望,但仍有很大的改进空间。生成语义一致的长文本文章对于LM来说仍然是一个具有挑战性的问题。因此,可以利用合成文章和真实文章中语义信息表示的差异来构建强大的防御”
当试图绕过deepfake文本检测器时,攻击者可能并不总是能够更改合成文本的语义内容,尤其是当这些文本旨在传达特定思想时。未来,这组研究人员收集的研究结果和他们创建的简化FAST模型可能有助于加强对在线合成文本的防御,从而可能限制大规模的虚假信息或激进化活动。
“目前,这个方向还没有在安全社区进行调查,”维斯瓦纳特补充道。“在我们未来的工作中,我们计划利用知识图来提取更丰富的语义特征,希望产生更高效和更强大的防御。”