
NIALM(非侵入式设备负载监测)可以“感知”使用电力的设备。NIALM用于家庭和小型建筑物。为此,NIALM可能需要来自每种设备类型的数百个标记的电源信号图像来进行训练。但是,有一种比“传统”机器学习更快、更具成本效益的方法。
约翰内斯堡大学的研究人员为NIALM部署了FewShotLearning(FSL)。经典FSL只需要10张带标签的分类图像即可以非常高的准确度识别电器。
他们调整了流程,以便AI(人工智能神经网络)可以自行选择最佳训练图像。这使得训练过程更快。当他们还调整了一些超参数时,只要七张测试图像就足以让FSL以97.83%的准确率识别电器。根据测试期间的类数,一张训练图像(一次性学习)的准确率为88.17%到91.343%。
他们的研究发表在ComputationalIntelligenceandNeuroscience上。
FSL:当机器学习时
教AI识别电器的电源信号通常需要大量数据。通常,人工智能需要数百张由人类标记的图像,以识别每种设备类型,尽管容量和运行状态不同。一台设备的两种操作状态的示例是洗衣机的洗涤和旋转循环。
AI的所有训练数据都必须由人类创建和标记,这很快就会变得缓慢且昂贵。
但是人工智能还有另一种学习方式,它确实需要非常少的标记数据。只需10张带标签的训练图像就足以进行极其准确的图像分类。
例如,假设一个AI以这种方式训练了十张大象、老虎和熊的图像。当使用未标记的大型雄狮图像测试AI时,AI应该能识别出狮子与老虎相似,但又不相同。然后人工智能应该自己决定为狮子创建一个新的对象类。
此外,当AI面对未标记的幼狮图像时,它应该能够将幼狮与雄狮归为同一类。
这种类型的AI机器学习(ML)算法称为少样本学习(FSL)。它是元学习或“学会学习”的一种形式。
FSL已经为占主导地位的全球科技公司提供了巨大的语言模型。在一些机场检查护照与旅客面部的计算机视觉系统也使用FSL。
猫的部位
UJ电气与电子工程科学系的YanxiaSun教授说,小样本学习实际上是用一些数据训练AI神经网络,甚至是关于对象类别的不完整数据。孙是这项研究的主要作者。
“当我们用训练图像训练神经网络时,人工智能会自己学习每只动物或物体的特征。”
在老虎对狮子的例子中,FSLAI从老虎图像中学习胡须、猫眼、毛皮和猫尾巴。它以前从未见过狮子。但是当人工智能用狮子的图像进行测试时,它应该将狮子识别为与老虎相似但不相同的对象类别。
NIALM:一个功耗表适用于多种电器
NIALM用于小型商业建筑或家庭,以测量每台电器或设备消耗的电量。
NIALM使用功率分解来分离在同一电相位上同时打开的许多电器的组合功耗信号。NIALM仅使用一种测量设备。这比必须依次将功率计物理连接到每个设备要容易和快捷得多。
一些国家的家庭智能电表存储每台电器的耗电量数据,并将其发送给电力公司。在其他国家,智能电表也为房主提供能源消耗数据。
功耗信号转数字图像
在这项研究中,研究人员在来自各种家用电器的电力负载信号的NIALM图像上训练了他们的FSLAI。
他们通过将功率分析仪(TektronixPA1000)插入并依次将每个设备插入多插头电源扩展器来获取功耗信号。然后他们打开功率分析仪。然后打开和关闭设备,同时功率分析仪随时间记录功耗。对于笔记本电脑和台式电脑,整个启动序列都被记录下来。
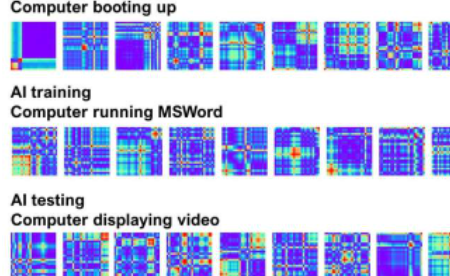
约翰内斯堡大学的研究人员测试了一种用于识别家用电器电源信号的小样本学习(FSL)算法。随着测试图像数量的增加,平均准确率从最低的91.343%增加到最高的97.83%。图片来源:ListonMatindife和TheresevanWyk。来自计算智能和神经科学研究的数据。(DOI:10.1155/2022/2142935)creativecommons.org/licenses/by/4.0/
功率分析仪将电器的模拟功耗信号转换为数字数据。然后将该数据转换为格拉姆角求和场(GASF),它看起来像色彩鲜艳的瓷砖。
然后将400X400像素的彩色GASF图像转换为灰度图像,并将尺寸缩小为28X28像素。这降低了算法的复杂性并使用了更少的计算资源。
加快训练
经典FSL是一个两阶段过程——训练和测试。在这项研究中,研究人员增加了一项调整,以加快选择非常适合训练的数据,这也将加快训练过程本身。
该研究的第一作者ListonMatindife博士说:“我们通过对数据进行度量学习的难易程度或适用性进行初步评估,提高了FSL算法的准确性。我们称之为相似性测试。”
在研究期间,Matindife是一名博士。约翰内斯堡大学的候选人。他目前在津巴布韦国立科技大学任教。
“如果GASF图像未通过相似性测试,则意味着数据在转换为GASF图像之前需要进行更多预处理,尤其是时间序列或波形格式。通过相似性测试的图像使我们的模型能够更快地学习,”添加Matindife。
训练和测试FSLAI
为了训练FSLAI,研究人员为其提供了研究中14类电器中10类的GASF图像。他们为每个电器类别使用了10张图片:打开的笔记本电脑、运行MSWord的笔记本电脑、台式电脑、冰箱、双板炉和各种低能耗灯。
然后他们测试了FSL人工智能,看看它学会识别或分类器具的能力如何;并学会为它以前从未见过的设备创建新类。
为了进行测试,他们向FSLAI提供了4个新类别的图像,每个类别10张图像:一台显示视频的笔记本电脑、一台微波炉、一个水壶和一个紧凑型荧光灯(CFL)。
高精度,图像少
对于笔记本电脑测试图像,FSL算法将测试图像分类(识别)为来自笔记本电脑的功耗信号,但处于新的运行状态,准确率为97.83%。这种新的操作状态正在显示视频,而不是像训练图像中那样启动或运行MSWord。
FSLAI仅用七个用于启动的测试图像和另外七个用于运行MSWord的测试图像就达到了这种精度。
从少样本学习到单样本学习
研究人员还改变了训练图像的数量,然后测量了算法的分类精度。测试表明,随着每类测试图像数量的增加,平均准确率从最低91.343%提高到最高97.83%。这表明FSL可以应用于NIALM识别。
“NIALM算法开发涉及大量数据。对于激活周期不同的电器,我们将为每个电器生成不同数量的数据集图像。不同电器的训练图像数量不平衡通常会影响训练算法,”Matindife说。
“我们的算法减少了对昂贵的设备特定数据获取的需求。使用原型网络FSL算法可以毫无困难地输入具有不同数量样本图像的设备数据集,”他补充道。
这项研究表明,当使用基于应用于GASF图的计算机视觉的连体和原型FSL算法时,每个类只需一张训练图像就可以实现90%的平均准确率。当一张训练图像产生足够的精度时,它被称为一次性学习。Matindife说,一次性学习可以解决NIALM中的一个巨大挑战——需要大量的训练图像。
防患于未然
Sun说,这种FSLNIALMAI可用于识别无法正常工作的高价值设备,例如计算机或冰箱,其中电源或压缩机电机开始缓慢走向故障。
FSLAI可以用几张来自功能良好的家用冰箱的电源信号图像进行训练。第一台冰箱来自品牌A和容量B。
然后在家庭或小型商业建筑中,如果AI看到来自品牌C和容量D的压缩机电机出现问题的家用冰箱的电源信号,它应该能够标记第二个设备有电源信号问题,她说.